🌀 The Paradox of Velocity in AI Coding
After sprinting through two weeks of AI-coded progress—and crashing into drift, chaos, and broken trust—I reset everything. This is the story of slowing down, building real structure, and defining a repeatable AI‑Ops workflow. From vibe coding to teardown, here’s what I learned.

Slowing down to speed up (for real this time)
Two weeks.
That’s how long it took to go from zero to a fully functioning, AI-coded app in production.
And then—in just two days—I had to burn it all down.
Not because the tools failed.
Because I moved too fast.
Because AI lets you skip to the end before you understand what it takes to build the middle.
⚡️ Week 1–2: Vibe Coding at Full Throttle
I fell into the exact trap many developers do when working with AI for the first time: vibe coding.
It’s fast. It’s fun. It works—until it doesn’t.
With tools like Lovable and Kilo, I was able to:
- Scaffold out full features in hours
- Generate edge functions, DB schemas, and UI hooks in one shot
- Patch bugs with a single prompt
- Deploy to production before I’d even documented anything
It felt like magic.
But here’s the thing about magic: it doesn't debug itself.
By the end of Week 2, I had a working app—but I couldn’t trust it anymore.
Under the hood, it was chaos:
- Type drift between frontend and backend
- Styling drift from semantic tokens to raw Tailwind classes
- Unlogged changes to Zod schemas
- Inconsistent folder conventions
- Silent breakages caused by copy-pasted-but-regenerated functions that looked identical but behaved differently
Every patch introduced more entropy.
Every AI-assisted “fix” amplified the drift.
Eventually I realized:
🏚️ It felt like remodeling a 50-year-old house—no permits, no plans.
Sure, the walls looked fine at first. But the moment I opened them up?
No insulation. Live wires spliced with duct tape. Plumbing duct-taped to HVAC.
I let AI build fast—but I hadn’t enforced any standards.
I could patch it. Paint over it. Hide the drift.
Or I could tear it down and rebuild it with the structure I wish had been there from the start.
So I shut it all down.
Reset the repo.
Started over.
🧹 Week 3: Slow Is Smooth, Smooth Is Fast
Now it’s Week 3.
I’m starting from scratch—but this time, I’m slowing down to speed up.
Not slowing the AI down.
Slowing me down.
Slowing the feedback loop.
Slowing the decisions to ensure they stick.
Because here’s the paradox I’ve now lived firsthand:
With AI, you can move fast—but you shouldn’t.
✅ The AI‑Ops Flow I’m Testing Now
This isn’t a framework. Yet.
But it’s working better than anything I’ve done before. And it’s already showing signs of being teachable, repeatable, and enforceable.
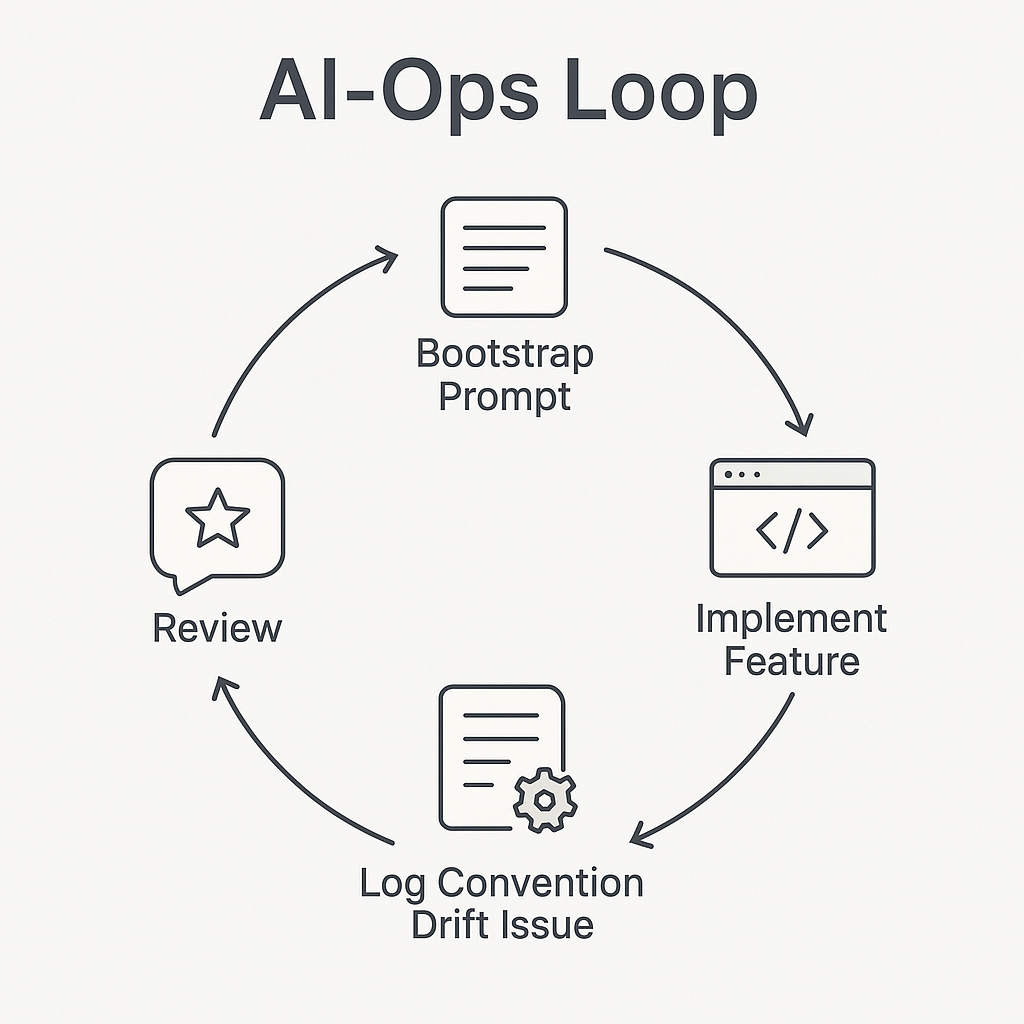
Here’s the loop:
1. 🏗 Bootstrap Prompt First
No UI. No features.
Just foundational setup:
- Folder structure
- Type and schema contract boundaries
- Theme token map
- Naming conventions
- Clear file responsibilities
I treat this like setting the load-bearing walls of a house.
No rooms get built until the beams are in place.
2. 🔁 One Feature at a Time
Each new capability gets its own scoped prompt.
No multitask prompts. No “do it all” requests.
Each function, view, or interaction starts with:
"Here’s the structure. Generate this feature inside it."
Once it works, I ask for a “replay prompt” to save and reuse later.
That prompt becomes the source of truth for regeneration.
3. 📂 Log Everything
To fight entropy, I log every outcome manually.
Drift, bugs, fixes, conventions—it all gets saved.
ai-code-issue-001.log // Root Cause Analysis (RCA)
ai-code-convention-001.md // New standards born from an issue
ai-code-drift-001.txt // Divergence from prior expected behavior
ai-code-review-001.md // Raw GPT critique of new code
ai-code-review-001-reprompt.md // Refactor prompt based on review
Each file represents a breadcrumb in my AI coding journey.
Together, they form the beginning of a system of record—a git-like trail for prompt-based coding.
4. 👨⚖️ Use World-Class Reviewer Mode
I wrote a “world-class software reviewer” prompt stack for ChatGPT.
Every new edge function gets reviewed:
- For structure
- For clarity
- For safety
- For architectural fit
The review + reprompt combo lets me close the loop and hold the AI accountable to my conventions, not just its own training.
5. 🛡️ Enforce the Paradox
Slow down.
Keep the loop tight.
Don’t let AI outpace your understanding.
I don’t let AI write more code than I can debug.
I don’t let it implement a feature I can’t replay from a clean prompt.
I don’t ship anything until I understand exactly why the output works—and where it might break.
🔍 Am I Just Reinventing the Wheel?
Not exactly.
I went and checked. Others are arriving at similar conclusions:
- Andrej Karpathy himself has publicly warned developers to “keep AI on a leash”—calling out how large language models can produce fast but fragile code if you don’t slow the loop (Business Insider).
- Security researchers recently found that nearly half of AI-generated code contains vulnerabilities. Especially when developers vibe-code without constraints or review systems (TechRadar).
- A recent study on perceived vs. actual productivity with AI tools found that AI feels faster but can often lead to more rework, worse clarity, and slower long-term delivery unless used intentionally (TIME).
- Mailchimp’s enterprise use of vibe coding yielded a 40% speed boost—but only after implementing layered governance. They learned that fast requires accountability. I’m applying those lessons at the prompt level with AI‑Ops. (ARTIFICIAL IGNORANCE)
So yes—I’m circling something real.
But I’m also formalizing it in a way most people haven’t yet.
📦 What’s Still Missing
I’ve only just begun.
But even now, I can see what’s next:
- Structured README + developer guide generation
- CI/CD hooks that validate replay prompts and enforce conventions
- Semantic drift detectors for schema/type/style divergence
- A “project memory” dashboard that maps logs and conventions across time
- Full audit trails of AI contributions, versioned like code
- An AI project assistant that acts like a codebase SRE
If this workflow proves sustainable, I’ll codify the whole thing.
Not just as a guide—but as a toolkit, a real-world AI‑Ops implementation system.
🧠 Defining AI‑Ops
If DevOps is the discipline of managing code delivery at scale…
And ModelOps is the discipline of managing ML models at scale…
Then AI‑Ops, as I’m defining it, is:
A deliberate engineering methodology where AI-generated code is treated like any operational asset: versioned, reviewed, audited, and continuously governed through prompt conventions, drift controls, RCA cycles, and human-in-the-loop validation.
It’s not about building faster.
It’s about building intentionally, even when the AI can move faster than you can think.
🏃♂️ This Feels Like Couch → 5K → Marathon
Three weeks ago, I was barely jogging through AI prompts, just seeing what worked.
Now, I’m running structured loops, tracking issues, logging drift, reviewing every feature.
This isn’t sprinting.
It’s training.
- Week 1: Couch to 5K — hype, hallucinations, and a working prototype
- Week 2: 5K to injury — fragility, drift, and systemic failure
- Week 3: Marathon mindset — pacing, structure, and operational resilience
This whole process?
It’s not about how fast you can go.
It’s about how far the system can carry you.
🔦 Look at Me (Yes, Actually)
I’m not the kind of person who shouts “expert” from the rooftops.
Usually, I’d rather keep building than post about it.
But let’s be honest:
- I’ve spent the past three weeks coding side-by-side with AI, day and night
- I’ve burned two prototypes to the ground
- I’ve rebuilt one from scratch with a working manual RCA, prompt logging, and review system
- I’m now tracking conventions, drift, and replays with the discipline of an SRE but applied to prompt engineering
- I’ve validated this approach against the current frontier of AI coding practices
- And I’m actively shaping it into a repeatable, enforceable, teachable system
So yeah—this is me calling it out.
Not because I think I’ve “arrived.”
But because I’m doing the work and naming the patterns as I go.
If that makes me an expert-in-progress on AI‑Ops, so be it.
If nothing else, I’m someone with a few battle scars, a lot of documentation, and the humility to know that week four might still punch me in the face.
But now?
At least I’ll log it.
📎 Appendix: AI‑Ops, SRE, and the Meta Layer
What is AI‑Ops?
A deliberate engineering discipline for AI-assisted software development, where prompt-generated code is versioned, reviewed, audited, and governed like any other operational system.
What is SRE in this context?
SRE = Site Reliability Engineering — a practice from Google that focuses on system reliability, incident response, and automation. I apply SRE principles to prompt workflows:
- RCA logs →
ai-code-issue-###.log - Prompt conventions →
ai-code-convention-###.md - Drift tracking →
ai-code-drift-###.txt - AI code review → prompt stacks with reprompt files
- Replayable artifacts → Prompts-as-Code
Why this matters:
This isn’t about speed. It’s about durability.
The AI can help build faster than ever — but only if we treat the system around it with the same discipline we apply to production infrastructure.
Enterprise echoes:
Mailchimp’s adoption of vibe coding produced measurable speed gains—but only once guardrails were layered in. That mirrors my own teardown and rebuild strategy—with prompt-level governance from day one. (VENTURE BEAT)

